



廣東智慧教育研究院師生論文被國際人工智能頂級會議AAAI 2025錄用
暨南大學融媒體中心訊 2024年12月,美國人工智能協會 AAAI公布了2025年的論文錄用結果,暨南大學廣東智慧教育研究院師生投稿的六篇文章順利入選,文章涉及到基于注意力機制的知識追蹤、認知波動增強知識注意力網絡、階梯式獎勵模型等研究內容。
AAAI全稱為國際先進人工智能協會(Association for the Advancement of Artificial Intelligence),是人工智能和機器學習領域的頂級會議,據最新中國計算機學會(CCF)推薦國際學術會議和期刊目錄,AAAI為人工智能領域的A類會議。AAAI 2025會議共有12,957篇投稿,接收率僅為 23.4%。會議將于2025年2月25-3月4日在美國賓夕法尼亞州費城召開。

入選論文介紹
論文題目:Rethinking and Improving Student Learning and Forgetting Processes for Attention based Knowledge Tracing Models
作者:白友恒(暨南大學)、李薛毅(暨南大學)、劉子韜(暨南大學)、黃雅瑩(暨南大學)、田密(好未來)、羅偉其(暨南大學)
通訊作者:劉子韜
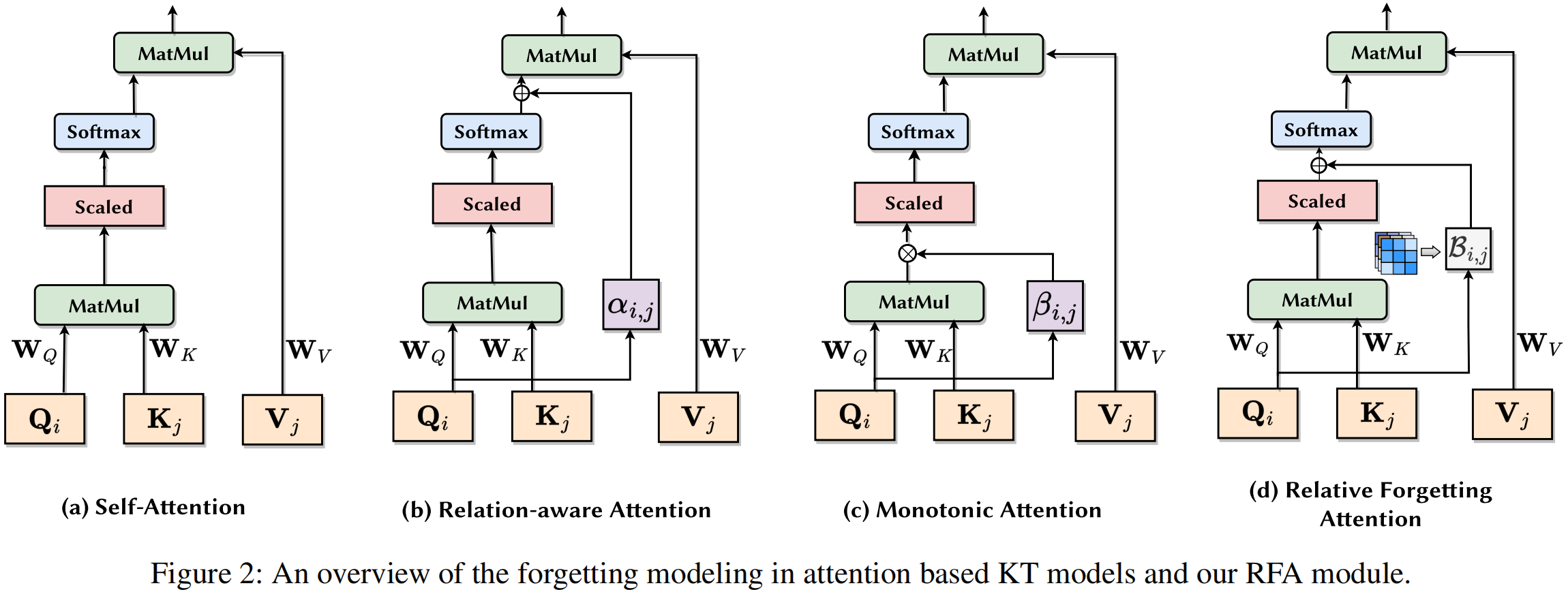
成果簡介:知識追蹤(KT)對學生的知識狀態進行建模,并根據他們的歷史交互數據預測他們未來的表現。然而,基于注意力的 KT 模型很難準確捕捉不斷增長的交互序列中的各種遺忘行為。首先,現有模型使用統一的時間衰減矩陣,導致遺忘表征與問題相關性混淆。其次,固定長度窗口預測范式無法對擴展序列中的連續遺忘過程進行建模。為了應對這些挑戰,本文引入了 LFPKT,這是一種統一的架構,通過結合提出的相對遺忘注意力來增強基于注意力的 KT 模型。LFPKT 通過相對遺忘注意力來改善遺忘建模,以實現與問題相關性的解耦。此外,它還增強了基于注意力的 KT 模型的長度外推能力,用于捕獲不斷增長的交互序列中的連續遺忘過程。三個數據集上的實驗結果驗證了 LFPKT 的有效性。為了鼓勵可重復的研究,我們將數據集和代碼公開在https://pykt.org/。
論文題目:Cognitive Fluctuations Enhanced Attention Network for Knowledge
作者:侯明良(好未來)、李薛毅(暨南大學)、郭騰(暨南大學)、劉子韜(暨南大學)、田密(好未來)、羅仁強(大連理工大學)、羅偉其(暨南大學)
通訊作者:郭騰

成果簡介:知識追蹤(Knowledge Tracing,KT)是一項序列預測任務,旨在利用學生的歷史學習交互數據預測其在未來問題上的表現。KT的核心在于對人類認知行為的建模,以加深對認知過程的理解。人類認知具有兩個關鍵特性:一是長期認知趨勢,反映知識隨著時間逐漸積累和穩定的過程;二是短期認知波動,源于遺忘或注意力暫時失焦等瞬時因素。現有的基于注意力機制的KT模型雖然能夠有效捕捉長期認知趨勢,但往往難以充分處理短期認知波動。這些局限性導致認知特征過于平滑,從而降低了模型性能,特別是在測試數據長度超過訓練數據長度時表現尤為明顯。為了解決這些問題,我們提出了FlucKT,一種增強短期認知波動建模的注意力網絡,用于KT任務。FlucKT從以下兩方面改進了注意力機制:首先,通過基于分解的層和因果卷積,分離并動態重權重長期與短期認知特征;其次,引入了核化偏置注意力分數懲罰,以強化對短期波動的關注,從而提升模型的長度泛化能力。我們通過在三個真實數據集上的廣泛實驗驗證了FlucKT的貢獻,實驗結果表明,該模型在長度泛化能力和預測性能上均取得了顯著提升。
論文題目:What Are Step-Level Reward Models Rewarding? Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning
作者:馬奕然(浙江大學)、陳醉(上海科技大學)、劉天喬(好未來)、田密(好未來)、劉卓(University of Rochester)、劉子韜(暨南大學)、羅偉其(暨南大學)
通訊作者:劉子韜
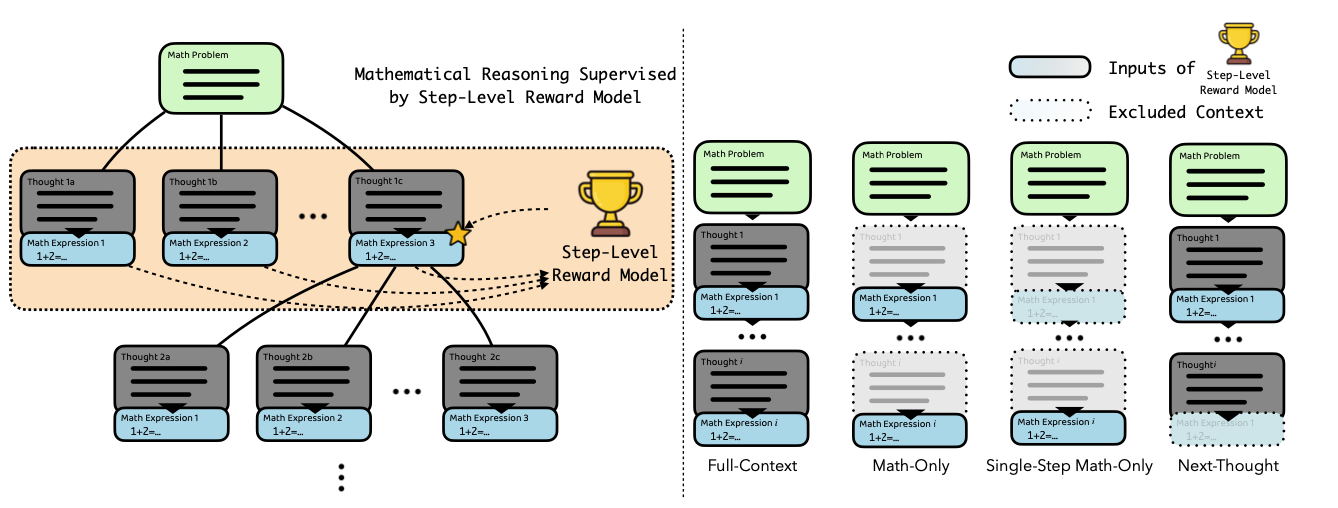
成果簡介:步驟級獎勵模型(SRM)可以通過過程監督或基于強化學習的步驟級偏好對齊,顯著提升數學推理性能。SRM 的性能至關重要,因為它們作為關鍵的指導方針,確保推理過程中的每一步都與預期的結果一致。最近,類似 AlphaZero 的方法,使用蒙特卡羅樹搜索(MCTS)進行自動步驟級偏好標注,被證明特別有效。然而,SRM 成功的精確機制仍然尚未被深入探討。為了解決這一空白,本研究深入探討了 SRM 的一些反直覺方面,特別關注基于 MCTS 的方法。我們的研究發現,移除思維過程的自然語言描述對 SRM 的效能影響甚微。此外,我們證明了 SRM 能夠擅長評估數學語言中復雜的邏輯一致性,而在自然語言方面則存在困難。這些見解為有效的數學推理中步驟級獎勵建模的核心要素提供了細致的理解。通過揭示這些機制,本研究為開發更高效、更簡化的 SRM 提供了寶貴的指導,這可以通過專注于數學推理的關鍵部分來實現。
論文題目:A Syntactic Approach to Computing Completeand Sound Abstraction in the Situation Calculus
作者:方良達(暨南大學)、王曉曼(暨南大學)、陳長(暨南大學)、羅凱倫(東莞理工大學)、崔振河(湖南科技大學)、官全龍(暨南大學)
通訊作者:官全龍
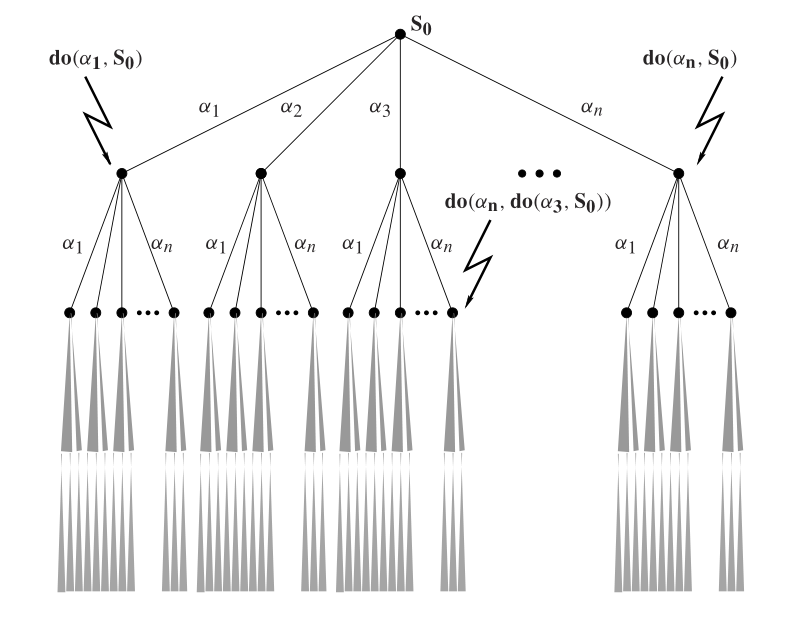
成果簡介:抽象是人工智能領域中一個重要且有用的概念。據我們所知,目前還沒有一種句法方法可以從給定的低階基本動作理論和細化映射中計算出完備且正確的抽象動作理論。本文旨在解決這個問題。為此,本文首先提出一種情景演算的變體,即線性整數情景演算,它用作高階基本動作理論的描述框架。然后,本文將Banihashemi、De Giacomo和 Lesperance三人提出的抽象框架遷移至一個從線性整數情景演算到擴展情景演算的框架。此外,本文確定一類 Golog 程序,即受限動作,用于限制低階 Golog 程序,并對細化映射施加了一定的限制。最后,本文設計一種句法操作,用于從低階基本動作理論和受限細化映射中,計算出完備且正確的抽象動作理論。
論文題目:Vision Transformers Beat WideResNets on Small Scale Datasets Adversarial Robustness
作者:鄔鈞陶(暨南大學)、宋子玉(暨南大學)、張曉鈺(暨南大學)、謝淑君(暨南大學)、林龍新(暨南大學)、王苛(暨南大學)
通訊作者:王苛
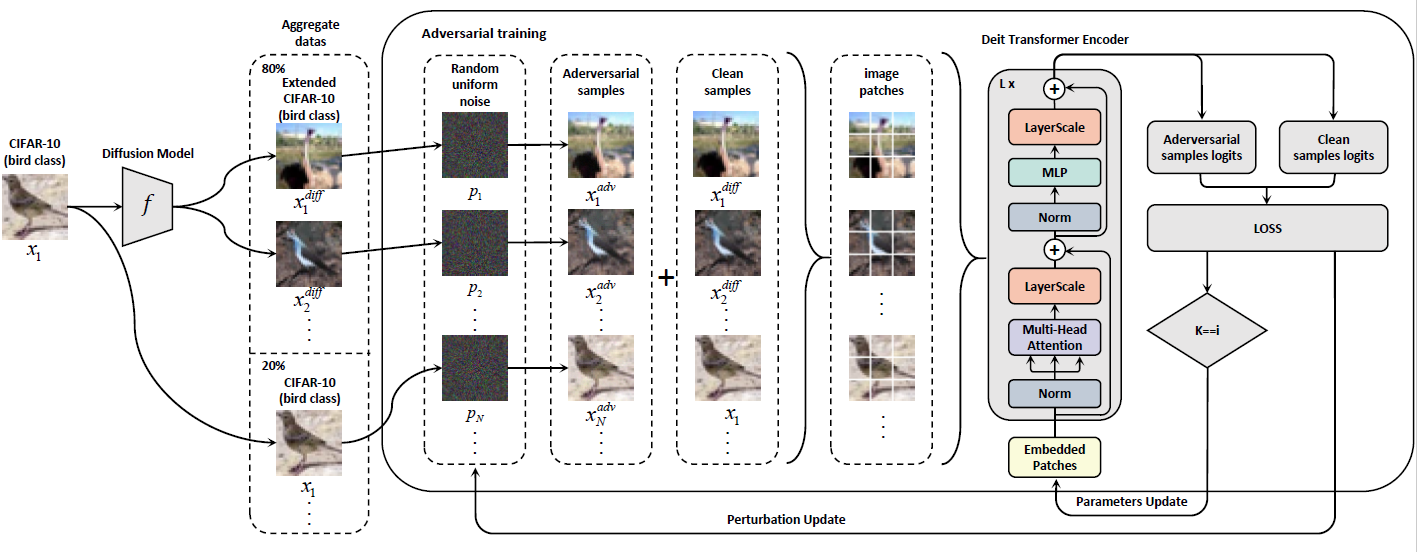
成果簡介:在長時間內,Vision Transformers(ViTs)一直被認為不適合在小規模數據集上獲得強大的表現,而WideResNet模型則在這一領域占據主導地位。盡管WideResNet模型在CIFAR-10和CIFAR-100等數據集上持續設定了最先進的(SOTA)魯棒性準確率,但本文挑戰了只有WideResNet能夠在這一背景下表現優異的普遍觀點。我們提出了一個關鍵問題:ViTs是否能夠超越WideResNet模型的魯棒性準確率?我們的結果給出了一個肯定答案。通過結合擴散模型生成的數據進行對抗訓練,我們證明了ViTs確實可以在魯棒性準確率方面超越WideResNet。具體而言,在無窮范數威脅模型下,epsilon = 8/255時,我們的方法在CIFAR-10上達到了74.97%的魯棒準確率,在CIFAR-100上達到了44.07%的魯棒準確率,相較于之前的SOTA模型,分別提高了+3.9%和+1.4%。值得注意的是,我們的ViT-B/2模型,參數量是WRN-70-16的三分之一,且超越了此前表現最好的WRN-70-16。我們的成就開辟了一條新道路,未來采用ViTs或其他新型高效架構的模型,可能最終取代長期主導的WRN模型。
責編:周會謙